As server farms start to dominate the computer business, there is a specter casting a shadow. The huge energy consumption of these farms. Google has suggested reducing the A/C cost by putting the farms on ships and using sea water to cool them. Maybe they should add OTEC or wave power too. I pity the poor sods on board maintaining the systems.
Now Technology Review reports on an experiment to use smaller, more efficient and far less power hungry computers for a farm. FAWN (Fast Array of Wimpy Nodes) is a server bank using the CPUs and memories from net book computers. For applications that just need to deliver small amounts of data, this approach turns out to be faster and cheaper than conventional servers. The reason being that the IO bottleneck is usually the disk reads. Thus using lots of small processors and DRAM memory for storage, the server arary can deliver more requests. The 2 papers to be published can be obtained from the author's website http://www.cs.cmu.edu/~dga/ or directly from here and here. Interesting reading.
Which leads me to a further idea. Why cannot we use smart phones as a cloud? Here were have the fastest growing market for CPUs and memory. They are ubiquitous and sit idle for much of the day. What if they could be linked to offer a huge cloud for small messages? The phones would need to update the system with their current ip address and host some sort of lightweight web server. Security would need to be handled in a sandbox. If a webserver could be installed as part of the OS, there could be a distributed cloud that encompassed the globe. Running in memory on low power CPUs, just like FAWN, but with billions of nodes. Small, cheap and out of control. Indeed.
Food for thought.
Wednesday, April 22, 2009
Thursday, April 16, 2009
Cloud Dynamics
This is how I describe the dynamics of cloud computing. The first chart shows the model. The axes are computer workload vs. time to complete a task. The red line is for the client device, which is assumed to be less powerful than the server. The blue line is the latency of the connection to the server, the time it takes to deliver some data request and return a result. For a simple ping, this is of the order of 1/10 of a second or less, depending on traffic. Adding more data will increase the time as bandwidth is limited, which is why those Google maps can take forever to load on a smart phone over the cell network. The dark blue line is the total time for a request adding in the server's more powerful processing speed.
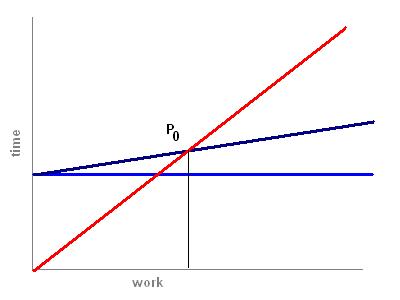
At point P0 is the break-even time. Tasks that take less work than this should be handled by the client device, while ones longer than this may be handled more effectively by the server, assuming the service wants to offer the shortest response time.
The next chart shows the effect of different clients. A PC is faster than a smart phone, so the break-even point is shifted to the left with a lower powered device. This means that more processing should be handled by the servers.

The third chart shows the effect of lower latency. If you could make the connection faster, again the server should take more load. In practice, the latency is mostly due to bandwidth limitations as data is moved between local device and server. Increasing bandwidth therefore makes servers more attractive.
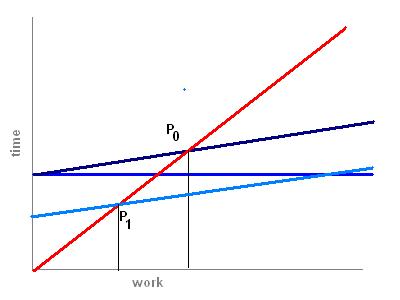
The fourth chart shows two extremes. The vertical orange line is for a dumb terminal that cannot do any processing. This isn’t an obsolete idea. Ultra thin clients might want to have no processing at all, e.g. to display signs, or just may want to prevent any processing at all. You can do this with your browser by turning off Java and Javascript.

The horizontal green line assumes that the server is infinitely scalable, rather like Google’s search engine. In this case, almost any task is computable in a short time.
So what does this tell us about the future? Firstly we know that the fastest growing market is the mobile market, whether smart phones or the new net books. This suggests that the drive to increase server processing in the cloud is going to increase dramatically. Desktop PCs and workstations however, will not likely benefit from the cloud doing the processing, so we can expect big applications to remain installed on the local machine and using the cloud simply for delivery of updates to the software.The war over bandwidth pricing implies that the providers will effectively keep bandwidth low and rates high, shifting the break-even to more local processing and hence driving up the demand for more powerful local devices. This will tend to stifle the growth of ultra thin client devices if unchecked.
For me, the interesting story is what happens if we can build extremely powerful servers, able to deliver a lot of coordinated processing speed to a task. In this case is may make a lot of sense to offload processing to the server like we do with search. One way to think about this is with the familiar calculator widget. Simple 4 function or scientific calculators can easily compute on the client, so the calculator is an installed application.
But what if you want to compute hard stuff, maybe whether a large number is prime? Then it makes sense to use the server as the task can be made easily parallel across many machines and the result returned very quickly indeed. Now the calculator will have more functionality, doing lightweight calculations locally and the heavyweight ones on the server. This approach applies to a lot of tasks that are being thought of today and is driving the demand for both platforms and software languages that can make this very easy to achieve.
Finally, let's look at a case where the server is slower than the client. There is no break-even point because the client device is always faster than the server.
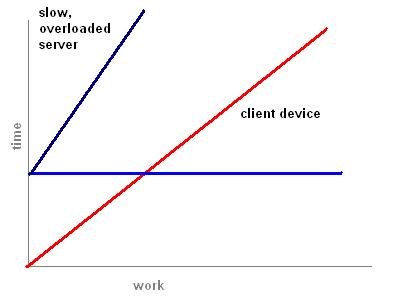
This scenario of the early days of the networked personal computer. Those were the days when networks were slow and servers, if they existed, were mostly simple file servers. It was also characterized by the period of extremely low bandwidth modems, preventing any reasonably fast computational turnarounds. In that world, it made sense to distribute software in boxes and install it on the client. This is still the dominant paradigm, even today, but it is clear that the advent of server farms and broadband, plus the demand for more lightweight mobile devices, will drive the cloud computing paradigm.
Stay tuned...
Wednesday, April 15, 2009
Courtesy of Marketing, Everything is Cloud Computing
I've been increasingly confused about where the boundary of 'cloud computing' is. At a recent cloud computing conference I attended, almost any approach was considered cloud computing. Grids, utilities, SaaS, ASP. You name it, some vendor was claiming it was cloud computing. No one can seem to clearly define it either, and I think that is deliberate. Marketing hype has stuck the 'cloud' label to everything to make their companies' products sexy, 'with it'. I swear I could convince an audience that a relabeled mainframe was a cloud computer.
And so it went at a talk I attended last night. The talk was entitled
The Business Value of Cloud Computing
and we had two engaging industry people talking about the cloud from opposite, but possibly complementary corners.
In the right corner was Paul Steinberg of Soonr.com. He spoke generically about SaaS (Software as a Service) and rolled out the usual suspects, GMail and Zoho Office as examples of this trend. Now I ask you, if GMail was delivered via a mainframe, would it suddenly lose it's cloud status? But conversely, if I throw up a web page on my ISP delivered website that has a rich client application in the page, would that be SaaS or cloud computing? At one point Paul said "SaaS is the same as cloud computing". Once the sales and marketing people get loose, you know the hype machine is in full swing.
In the left corner was Zorawar Biri Singh, from IBM. Biri presented us with some corporate IBM slides in a dizzying fashion, never allowing anything to be viewed in detail or explaining much. His role appeared to be to tell eveyone that IBM was in the cloud game and that their experience and dominance (in high end services?) would bring forth the goods in this arena. He had a couple of interesting details. Firstly, virtual machines were rapidly outstripping hardware machines. (Go out and buy VMWare NYSE: VMW ?) Secondly that while Amazon is selling CPU time for 10 cents an hour, he thought that the real cost might be closer to half a cent an hour. Do I hear 'supernormal profits' and IBM's rush to participate? One member of the audience questioned what sustainable advantage IBM might have in this game? Answer: "waffle, waffle, blah, blah, waffle". We've seen IBM do this before, last time it was SOA (service oriented architecture). IBM's solution was typically expensive and required a lot of IT and programmer time. Bottom like for Biri - cloud computing cuts costs. And IBM will be just the company to help you do that, no really.
So it looks like IBM is looking to build a rich server platform in the sky.
The problem with the cloud computing hype is that the customer doesn't care how the server parts work. In the same way I don't really know what fuels are delivered the power to my house. All I care about is that it is there and complain about it when the summer blackouts arrive. Most customers care about what it means for them. Is their client machine software going to be installed or web delivered? What feautures does it have? What does it cost? Where should teh data reside, and if the cloud, is it secure? Increasingly it will be "Can I get access to my software and data from any device, anywhere?". And increasingly that will mean mobile devices, from laptops to smart phone sized ones.
What few vendors talk about, is that the really power of the cloud is that software and data will increasingly be able to talk to each other out of their silos. That software will be able to draw on other software and data using a lot of resources to deliver really powerful information processing and delivery services.
Then the rain will fall on all of us.
And so it went at a talk I attended last night. The talk was entitled
The Business Value of Cloud Computing
and we had two engaging industry people talking about the cloud from opposite, but possibly complementary corners.
In the right corner was Paul Steinberg of Soonr.com. He spoke generically about SaaS (Software as a Service) and rolled out the usual suspects, GMail and Zoho Office as examples of this trend. Now I ask you, if GMail was delivered via a mainframe, would it suddenly lose it's cloud status? But conversely, if I throw up a web page on my ISP delivered website that has a rich client application in the page, would that be SaaS or cloud computing? At one point Paul said "SaaS is the same as cloud computing". Once the sales and marketing people get loose, you know the hype machine is in full swing.
In the left corner was Zorawar Biri Singh, from IBM. Biri presented us with some corporate IBM slides in a dizzying fashion, never allowing anything to be viewed in detail or explaining much. His role appeared to be to tell eveyone that IBM was in the cloud game and that their experience and dominance (in high end services?) would bring forth the goods in this arena. He had a couple of interesting details. Firstly, virtual machines were rapidly outstripping hardware machines. (Go out and buy VMWare NYSE: VMW ?) Secondly that while Amazon is selling CPU time for 10 cents an hour, he thought that the real cost might be closer to half a cent an hour. Do I hear 'supernormal profits' and IBM's rush to participate? One member of the audience questioned what sustainable advantage IBM might have in this game? Answer: "waffle, waffle, blah, blah, waffle". We've seen IBM do this before, last time it was SOA (service oriented architecture). IBM's solution was typically expensive and required a lot of IT and programmer time. Bottom like for Biri - cloud computing cuts costs. And IBM will be just the company to help you do that, no really.
So it looks like IBM is looking to build a rich server platform in the sky.
The problem with the cloud computing hype is that the customer doesn't care how the server parts work. In the same way I don't really know what fuels are delivered the power to my house. All I care about is that it is there and complain about it when the summer blackouts arrive. Most customers care about what it means for them. Is their client machine software going to be installed or web delivered? What feautures does it have? What does it cost? Where should teh data reside, and if the cloud, is it secure? Increasingly it will be "Can I get access to my software and data from any device, anywhere?". And increasingly that will mean mobile devices, from laptops to smart phone sized ones.
What few vendors talk about, is that the really power of the cloud is that software and data will increasingly be able to talk to each other out of their silos. That software will be able to draw on other software and data using a lot of resources to deliver really powerful information processing and delivery services.
Then the rain will fall on all of us.
Subscribe to:
Posts (Atom)